
Snowplow Analytics is a highly-scalable system that powers structured data creation for millions of sites on the internet. Snowplow tracking is incorporated into dbt, dbt cloud, Trello, Gitlab, Citi bank, Backcountry.com, and the list goes on.
After setting up data infrastructure like Snowplow for years I've frequently found myself wishing for both less and more.
Fewer streams, fewer machines or containers to manage, fewer moving pieces to help prevent event duplication or loss, less configuration, and less in-house documentation to keep things running would be a dream.
Deployment flexibility, flexible schema storage, cost efficiencies, seamless migration between transport systems, improved utility from the data in transit, and increased visibility would also be very helpful.
Meanwhile, serverless technologies have come into their own and point the way toward a very bright data-processing future. Which is how buz.dev was born.
Inspirations and iterations
My first iteration of "serverless Snowplow Analytics" was in 2018. I stitched together a Cloudfront distribution, a Python-based Lambda function, S3, and the Snowplow javascript tracker to stockpile event data. A series of Athena external tables sat on top of the raw data and voila! Near-real-time analytics for practically free. It worked so well a blog post was written and other people were inspired to build or write about the same. The system ran hands-off with very little effort on my part, thanks to minimal moving pieces and AWS having the responsibility of keeping it up and running.
Serverless event collection worked very well at scale during my time at CarGurus. While we had a Snowplow Analytics implementation, a colleage wanted to see what AWS Lambda could handle. The marketing team sent enormous amounts of email using a combination of Iterable and Dyn, and each blast would result in production systems being absolutely swamped with tracking callbacks. The analytics team wanted data for analytics or tracking opt-outs, but nobody wanted to provision (normally unused) static infrastructure. Lambda was a perfect fit. The system continuously ramped from 0 to ~20k rps and back again, the AWS bill was laughably small, and it required virtually zero maintenance.
After setting up Snowplow for a NYC-based commercial real estate company, the VP of Technology (who is now @ Disney Streaming) pushed my implementation further with a simple Lambda function. Instead of being limited to Snowplow protocol payloads, the Lambda function collected arbitrary json payloads, reformatted them as Snowplow Self-Describing Events, and fired them into the Snowplow collector. It was efficient and effectively hands-off. I have thought about his work ever since.
The rich benefits of serverless data processing for robotics and fulfillment were experienced while working at 6 River Systems (Shopify Logistics). Data volumes from fulfillment systems are highly variable. One warehouse or distribution center has a very different traffic pattern than another, but volume across all of them spikes to orders of magnitudes higher during Peak months. Over-provisioned infrastructure in an industry where margins are already tight is a complete non-starter. Serverless was the only option and did not disappoint.
And finally, my time working alongside Okta's security team has thoroughly solidified the value of serverless technologies in a security-conscious setting. Security teams absolutely love serverless tech. Want proof? Go check out Matano.dev, ask Panther how their systems are built, or dig into AWS marketing materials.
Serverless is the secret of highly efficient data processing. It is the way to make streaming accessible.
Why Build Buz?
While incredibly scalable and robust, setting up and maintaining OSS Snowplow is not for the faint of heart. It's time-consuming to set up, requires a deep understanding of the moving pieces to tune well, and requires significant engineering resources.
A very common Snowplow architecture diagram looks like the following, excluding monitoring, alerting, log centralization, and other devops necessities:
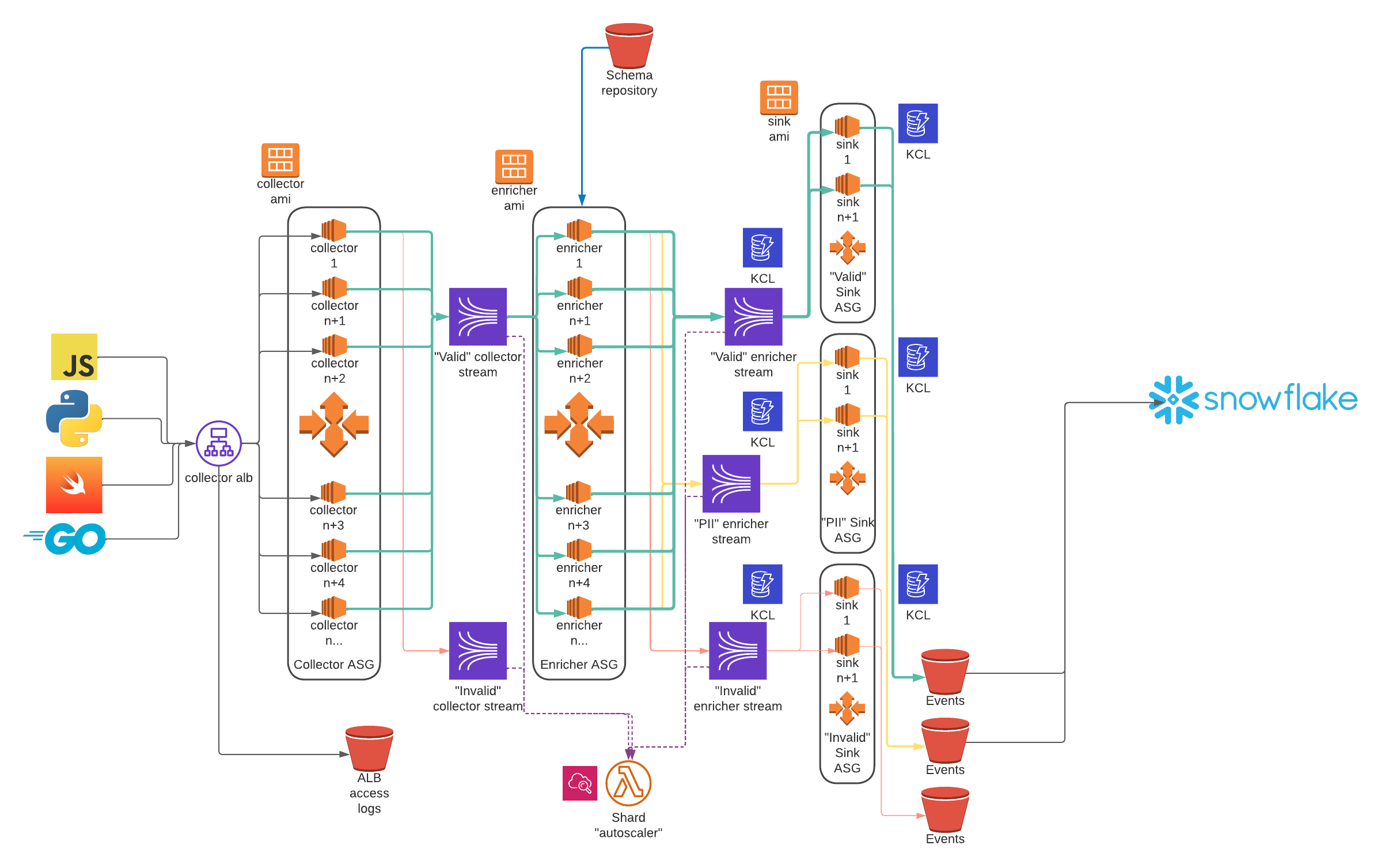
Opportunity costs matter to cost-conscious buinesses, and engineering resources dedicated to maintaining data pipelines are rarely the best use of said resources. Engineers also prefer to spend their time using streaming data rather than moving it around.
So my initial goal was to build a system like the following:

Snowplow tracking SDK's would be used for instrumentation. The serverless collector thing called Buz would collect, validate, and route payloads to S3 via Kinesis Firehose. And Snowflake would provide the compute on top of S3.
Buz Requirements and Design
Minimal human involvement to keep running
Systems are great when you don't need to think about them. In Julia Evans' words, spending approximately 0 time on operations was the goal.
Self-contained and capable of running horizontally with no issue
There's a movement of "small, mighty, and self-contained" afoot within data processing systems.
It's because complexity is hard to keep running.
Systems like Redpanda, which crams the Kafka api into a small self-contained binary, or Benthos, which crams cool stream-processing functionality into a small self-contained binary, are highly inspirational.
The Serverless Thing called Buz needed to do the same.
No JVM, no Spark, no Beam
Snowplow's collector, enricher, s3 sink, etc all run on the JVM.
Snowplow's RDB and Snowflake loaders run on Spark while the BigQuery loader runs on Beam (Cloud Dataflow).
But... Snowflake's Snowpipe works well, as do BigQuery streaming inserts or Pub/Sub subscriptions. And the responsibility of keeping Snowpipe or BQ streaming inserts running is offloaded :).
Serverless Thing was to shed as many dependencies as possible.
Fast startup and shutdown
Making containers fast to launch makes a big impact on cost as invocations ramp, so Serverless Thing had to be snappy. The faster infrastructure can follow the utilization curve, the more cost-effective it is. In an environment where costs are being scrutinized, doing work fast is just as important as not running at all when there is no work to be done.
Being efficient also happens to be pretty damn good for the environment. Burning fewer polar bears seems to resonate with others like DuckDB and 451 Research.
Payload validation, annotation, and bifurcation
A very valuable Snowplow feature lies at the Enricher, where each and every event is validated using the associated jsonschema.
The only way to do this quickly is via a self-warming schema cache, so an onboard cache became another requirement.
Just JSON
Snowplow data is serialized using thrift between the collector and the enricher but becomes tsv downstream of the enricher. This makes it hard to point a system like Materialize at the "enriched" stream without first reading tsv records -> formatting as json -> writing to a separate stream. Write amplification quickly becomes reality and the operator must make a choice between not reading from the stream or re-formatting every payload to something that is easily pluggable with other stream processing systems. At higher volumes this equates to $$$$$.
While JSON is not the smallest data format it is still more efficient to write JSON once than having many copies of smaller formats. I chose to have fewer copies but a larger per-record format.
This decision is tbd. Either way it's easy to change certain destinations to parquet.
Easy to configure
Yaml + Jsonschema validation is becoming pretty standard. It turned out to be a pretty good decision since auto-completing, auto-validating config is handy.
Serverless Thing had to be easy to configure. Bonus points for providing hints in an editor throughout the configuration process.
Make event streaming accessible
dbt has been so inspirational because it makes good data engineering practices accessible to all. Tricks that used to pay rent have become dbt packages anyone can import.
Like the data engineering of not-that-long-ago, today's streaming systems are intimidating. But they don't need to be. These systems are also often overkill. Transporting data via several streams only to batch-insert it into a Postgres database means the streaming infrastructure is unnecessary.
Serverless Thing should make streaming accessible, while making it easy to evolve from the current stack to some desired architecture. Even if that means shipping events to Postgres now and Kafka later.
Progress thus far
While Buz has much further to go, the journey of serverless event tracking has already been extremely worthwhile.
The pain and complexity of streaming systems seems to resonate with many people. Serverless fixes this pain.
Expanding to more inputs
I had a eureka moment early on - if the serverless model works using Snowplow's tracker protocol it should work for other protocols. As it turns out, it does! While also minimizing the hassle of running multiple event tracking pipelines - such as one pipeline for each protocol.
Cloudevents with its (optional) dataschema property was a low-effort addition. Fire payloads using the Cloudevents' data property, provide a schema reference in dataschema, and voila! Validated events without needing to write the sdk, or quickly hooking into tracking already in existence.
Pixels and webhooks were fun additions, mostly because these are often painful due to the arbitrary nature of their payloads. But another thought came to mind - validate these too! Since it would be fab to namespace and validate these payloads, named pixels and webhooks came to be.
Accepting self-describing json payloads was a nice addition, and provides some additional flexibility like custom top-level payload property names. It also makes internal SDK's a breeze to build.
In past work lives I've built lightweight sidecars to read Mongodb change streams or Postgres logical replication before writing data to systems like Kafka. Serverless Thing naturally lends itself to supporting change data capture, or at least the weird cousin of what CDC looks like today. A lovely example of what could (and/or should) be ubiquitous is Devoted Health's Avalanche project.
Writing events to a variety of destinations
Kinesis, Kafka, and Pub/Sub are commonly-supported streaming/transport mechanisms for data systems. All three options work well. But they are often overkill and debatably net-negative for:
- Companies with low data volumes or not big data
- Companies that don't need or want legitimately-real-time data access
- Non-production environments
- Local development
At CarGurus I learned the importance of making systems accessible to engineers, regardless of which environment they run in. Product engineers care about one thing: data gets to where it needs to be, wherever that is. They typically do not care about how it gets there or where it needs to be for downstream consumption.
At Shopify I learned the intricacies of building systems that can be deployed in single-tenant fashion as efficiently as multi-tenant.
Having flexibility to write data to a variety of systems is a requirement for all of the above, so Buz quickly expanded to support:
- Streaming destinations which are best in production at scale.
- Streaming hybrids like Kinesis Firehose, because they are hands-off and incredibly powerful for building data lakes.
- Traditional databases, because most every company has one already.
- Streaming databases, because they are the future.
- Timeseries databases, because they unlock some very interesting use cases.
- Saas products, because product and engineering teams everywhere use them.
- Message brokers, because they are well-loved and very useful.
Writing events to multiple destinations
Shopify has a streaming model where events are written to Kafka for distribution to Datadog for observability and to the data lake. A secondary model is simultaneously writing product/marketing events to Amplitude for product analytics and to the data lake. After seeing how simple yet operationally powerful these are, I had a hard time ignoring them.
Migrating systems is a very common pain point as needs, volume, and organizations evolve. Migrating from Postgres to Kafka or Kinesis to Kafka are common patterns, and dual writing is the way to do this without blowing everything up. I've often wanted to simply add a configuration block instead of writing a new system that will be thrown away after migration.
So Buz supports writing to more than one destination.
There are tradeoffs here that must not be ignored, as the risk of one destination being unavailable goes up pretty quickly when the number of them increases. It's a worthwhile ops lever nonetheless.
Flexible schema registry backends (including using the destination system as a registry)
I've often questioned why data processing systems rarely use the backend they ship data to for serving configuration, schemas, and other runtime resources. Many web apps do this - why don't data systems?
In the spirit of minimizing moving pieces, and because it's fun, Buz supports a variety of schema registry backends.
Interesting use cases this functionality unlocks include:
- Streaming analytics with no streams. Using Materialize as the destination as well as the schema registry means streaming insights don't rely on much infrastructure.
- Using Postgres as the application database, the event database, and the schema cache. Introducing event tracking to existing systems has literally never been easier.
- Analytics without a database at all. Using GCS or S3 for the schema cache and the data lake means a database is not required to get database-like results.
- Seamless tie-in to existing streaming workflows. If a Kafka or Redpanda schema is already in place, perfect! Yet-another-piece-of-infrastructure™ should not be necessary.
These unlocks are incredibly exciting.
Where do we go from here?
Thanks to serverless tech, we are in the early innings of complete data infrastructure transformation.
The serverless-first data processing idea seemed crazy for a very long time, but it's definitely not crazy. Companies like Modal and Panther have been built from the ground-up to power data-oriented serverless workloads, Fivetran leverages serverless for custom connectors, DuckDB can be easily tossed into a serverless function, database drivers are being retooled for serverless workloads, and the list goes on.
Serverless enables highly-efficient, secure, and low-footprint data workloads. It drastically lowers the complexity bar of data processing systems, and enables teams to spend less time on the boring stuff.
Buz will continue to be all-in on serverless because it makes streaming accessible.